실시간 CTR 분석 파이프라인 성능개선기

들어가기
고수는 장비 탓을 하지 않는다고 하지만, 저는 고수가 아니기 때문에 장비 탓 좀 하겠습니다.
노트북이 항상 최신 맥북 프로면 당연히 좋겠지만, 현실적인 비용 문제로 쉽게 교체하기가 어렵습니다.
제가 사용하는 노트북은 MacBook Air M1 · 8GB RAM으로 아주 훌륭하진 않지만 Kafka, Flink, Redis, Serving API, ClickHouse 정도는 Docker로 충분히 띄울 수 있습니다.
문제는 띄우는 순간 굉음이 시작된다는 겁니다. 마치 비행기 이륙할 때처럼요…
굉음이 너무 심해 이어폰을 껴보기도 했지만, 노트북 키보드를 사용하다 보니 발열이 손끝으로 고스란히 전해지더군요.
“이렇게 시달릴 수는 없어!”라는 생각이 들어 애플 공홈을 들어가 봤다가, 가격을 보고 다시 시달리기로 결정했습니다. 하지만 이 발열을 그대로 두면 배터리 성능은 녹아내릴 테고… 어떻게 해야 할까 고민하다 보니 이런 결론에 도달했습니다.
“아, 노트북을 바꿀 돈은 없으니 이 파이프라인 시스템을 최적화해야겠다. 안 되더라도 그냥 한번 해보자.”
이런 목표가 생긴 것이죠.
쾌적한 로컬 개발 환경을 사수하기 위해, 옆구리 살 같은 Redis와 Serving API를 제거하며 다이어트해 본 경험을 공유합니다.
1. 문제의 시작 : “내 노트북 팬이 멈추지 않는건 내 실력이 부족한 탓인걸까?”
개인 프로젝트로 CTR 데이터 파이프라인 시스템을 구축하고 이것저것 실험을 이어가던 중, Docker를 올릴 때마다 무서워졌습니다. 기본적으로 한 사이클을 돌려보기 위해서는 단 하나의 컨테이너도 빠짐없이 올려야 하는데, 올릴 때마다 팬 돌아가는 소리가 너무 괴랄했거든요..
기존 시스템 아키텍처는 이렇게 구성되어 있습니다.
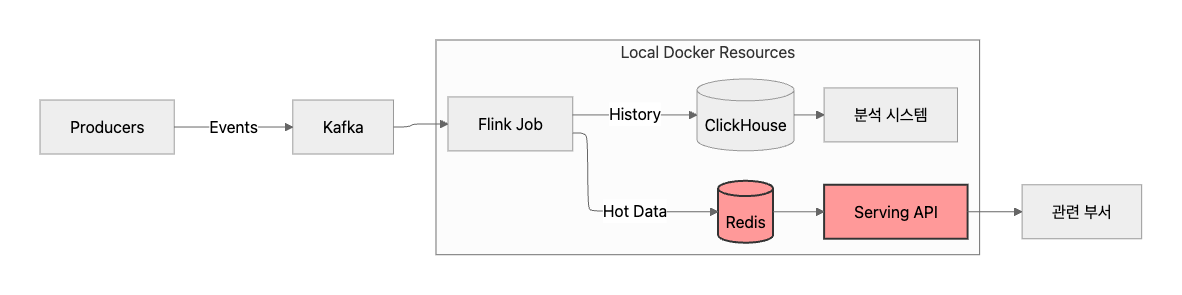
Kafka로부터 조회수와 클릭수 이벤트를 수신받아 집계하고 저장하는 과정에서 ClickHouse와 Redis에 데이터를 저장하고, ClickHouse는 분석용으로, Redis + Serving API는 관련 부서에 데이터를 전달하는 용도로 사용하고자 했습니다.
그런데 이렇게 구성해 보니 세 가지 Pain Point가 생겼습니다.
- 리소스 부족 : Redis + Serving API 컨테이너가 차지하는 Memory와 CPU 때문에 정작 중요한 Flink Job이 OOM으로 죽는 경우도 있었습니다.
- 관리 포인트 증가 : 집계 결과 변경으로 스키마가 바뀌면 Flink를 수정하고, Redis 데이터를 초기화한 뒤, API 코드까지 수정해야 해서 혼자 개발하는데도 Context Switching 비용이 너무 컸습니다.
- 네트워크 오버헤드 : 로컬 환경임에도 불구하고 Flink → Redis → API 과정에서 불필요한 직렬화/역직렬화 비용이 계속 발생했습니다.
가만히 생각해 보니 API를 조회하는 주요 고객을 ML 팀으로 가정했는데, 만약 사내 팀에서 ClickHouse로 직접 조회하는 것이 가능하다면 Redis와 Serving API를 제거할 수 있겠다는 판단이 들었습니다.
이 생각을 가지고 있던 중, 대기업에서 근무하는 친구에게 구축한 시스템에 대한 피드백을 받을 기회가 생겼습니다. 그 과정에서 Redis와 Serving API가 꼭 필요한지, 이 시스템에서 고려하는 상품 수는 얼마인지, Redis HashTable 특성상 리사이징 작업이나 키 업데이트가 일어날 때 조회 요청이 동시에 발생한다면 어떤 문제가 생길 수 있는지 등 여러 질문을 통해 Redis의 존재 자체에 대한 깊은 고민을 할 수 있었던 시간을 가졌습니다.
제가 설계한 의도에 대해 서로 논의했고, 결론적으로 두 가지 대안을 제시해 주었습니다.
- 지연 없이 적재 가능한 스토리지 포맷 사용 (예: Iceberg)
- ClickHouse의 Materialized View 활용 (약어로 MV라고 많이 사용함.)
2. 예측과 설계 : Redis + Serving API를 제거할 수 있겠다!
물론 Redis는 1ms 수준으로 빠르지만, 제 프로젝트의 목표와 제약을 다시 생각해봤습니다.
- 목표: 초당 10만건의 이벤트를 유실 없이 처리할 수 있는 시스템 구축
- 제약: MacBook Air M1, 8GB 기반의 로컬 개발환경, 리소스 최소화
- 가설: Redis 대신 대안을 사용해도 실시간성을 충분히 보장하면서도 복잡도를 낮출 수 있다.
또한 아키텍처 관점에서 보면, Serving Layer와 Storage Layer를 분리하는 관행이 오히려 시스템 초기 단계에서는 불필요하게 결합도만 높인다는 생각이 들었습니다.
3. 대안 선택 : Materialized VIew 활용
새로운 스토리지 포맷을 도입하는 것도 좋은 방법이지만, 제약 조건을 해결하고자 하는 마음이 컸기에 ClickHouse를 활용하기로 결정했습니다.
ClickHouse의 강력한 기능인 Materialized View를 활용하면, 별도의 애플리케이션 로직 없이도 데이터가 들어오는 순간 “미리 계산된 상태”를 만들 수 있습니다. 즉, ClickHouse 자체가 캐시 서버 역할까지 수행하게 되는 것입니다.
데이터 흐름
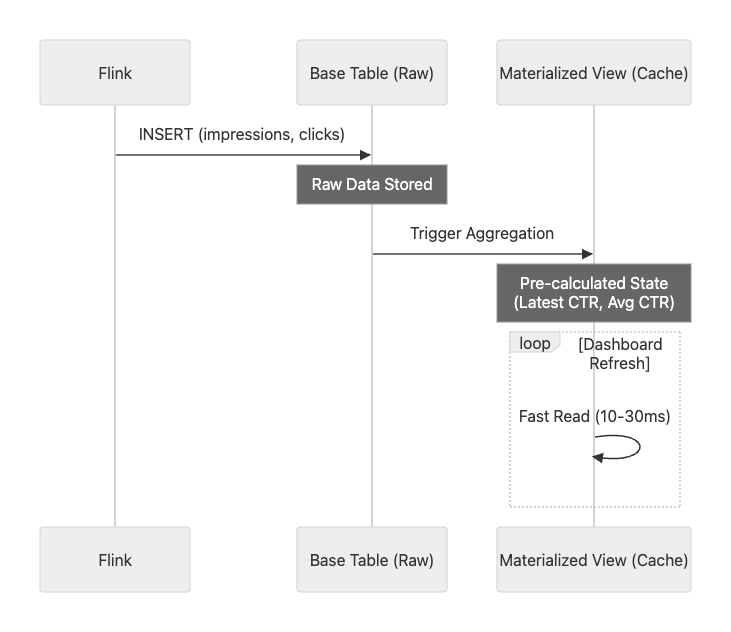
적용한 3가지 View 전략
ctr_latest_view: Redis의 Key-Value 조회를 대체. 항상 최신 CTR 상태만 유지 (ReplacingMergeTree).ctr_ml_view: 복잡한 집계 쿼리를 대체. 1분 단위로 미리 합계를 계산해 둠 (AggregatingMergeTree).- 효과: API 서버에서 처리하던
Merge로직이나Filtering로직이 모두 SQL 레벨로 내려가면서 API 컨테이너 자체가 불필요해짐.
4. 가설 검증
실제로 Redis와 Serving API 컨테이너를 제거하고 ClickHouse로 통합해 본 결과는 아주 매우 만족스러웠습니다.

🚀 성능 증명 (로컬 벤치마크)
성능을 측정하기 위해 테이블 캐시를 예열한 뒤 10회 조회하여 평균치를 계산했습니다. (TABiX 사용)
ex. SELECT count() FROM ctr_results_raw;
- 단건 조회: 0.00 ~ 0.01s (Redis의 1ms보다는 느리지만, 대시보드용으로는 충분히 빠름)
- 집계 조회: 0.02 ~ 0.05s (기존 Python API에서 직접 집계할 때보다 오히려 10배 이상 빠름)
정확하게 ms 단위까지 확인하고 싶었지만 툴의 한계로 10ms 단위까지만 확인 가능했습니다..
🧱 아키텍처 단순화 효과
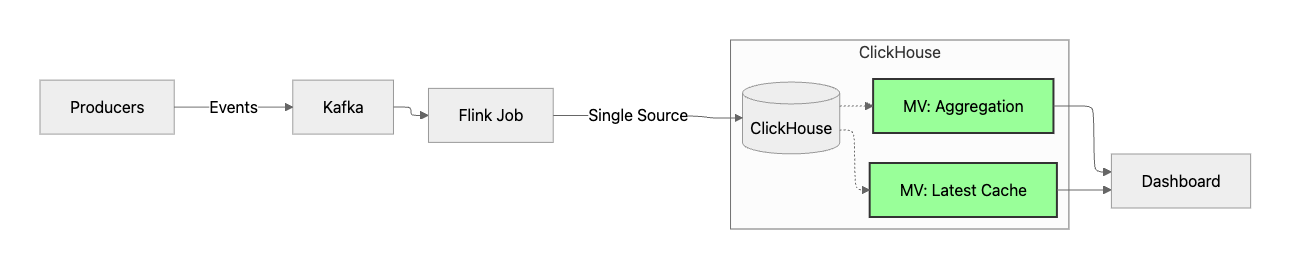
- Resource : Redis와 API 서버가 먹던 약 1GB의 메모리를 확보해 Flink에 더 할당할 수 있었습니다.
- SQL 중심 : 모든 데이터를 SQL 하나로 조회할 수 있어 디버깅이 훨씬 쉬워졌습니다.
- Deployment:
docker-compose.yml와 프로젝트 내부에 코드가 줄어들어 유지보수가 용이해졌습니다.
5. 아키텍처 변경 전후 비교표
| 항목 | 기존 구조 (Redis + API) | 개선 구조 (ClickHouse MV) |
|---|---|---|
| 주요 저장소 | Redis + ClickHouse | ClickHouse 단일화 |
| API 필요 여부 | 필수 | 불필요 |
| 리소스 사용량 | 1GB 추가 | 0GB (삭제) |
| 쿼리 복잡도 | Python API 로직 필요 | SQL로 단순화 |
| 지연 시간 | 1~3ms | 10~30ms |
| 처리량 | ~4k | 평균 20k, 스파이크 55k |
6. 느낀점
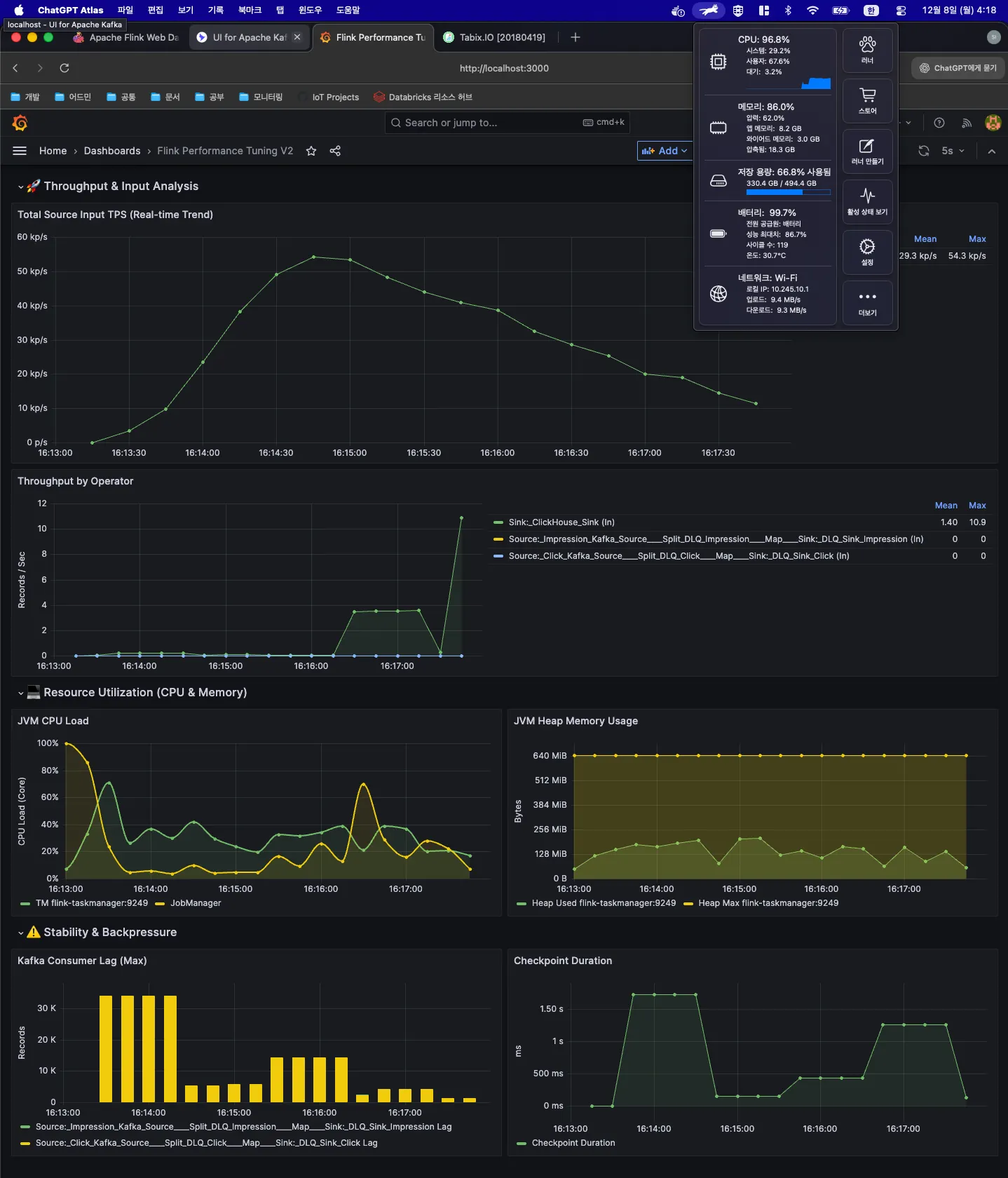
사실 처음에는 내 맥북의 사양이 낮아서 발생하는 문제라고 생각했습니다. 초당 833건의 데이터를 처리하는데도 버벅이며 팬이 엄청난 굉음을 냈기 때문이죠.
하지만 더 나은 시스템을 구축하기 위해 계속 고민하며 최적화를 하다 보니 처리량은 초당 4천 건까지 늘어났고, Redis + Serving API를 제거해 리소스를 확보한 뒤 Flink 앱에 자원을 더 할당하자 평균 1~2만 건을 처리하며 약 5.5만 건의 스파이크 트래픽도 안정적으로 소화할 수 있었습니다.
과연 최신 버전의 맥북을 사용해 처음부터 자원이 넉넉했다면, 이렇게까지 최적화를 시도했을까? 하는 생각도 듭니다. 오히려 이런 제한된 환경 덕분에 Flink를 더 깊이 살펴보고, 최적화를 위한 여정을 경험할 수 있었던 것 같습니다.
아직 이 시스템이 완벽하다고는 생각하지 않습니다. 최소 10만 건의 스파이크 트래픽을 견딜 수 있도록 더 최적화하며, 지속적으로 성장시켜 보려고 합니다.