실시간 CTR 분석 파이프라인 구축기
1. 프롤로그
데이터 엔지니어링 직무에 관심을 가지게 된 이후 10억행 챌린지(1BRC)를 해보면서 단순히 기술들을 사용하여 대용량 데이터처리가 잘 되는지 결과만 확인했습니다.
핵심은 단순 결과가 아니라, 설계부터 시작해서 운영까지 책임지며 현재 시스템에 적합한 설정을 찾아가는 과정이 중요하다고 생각되어 역량을 기르기 위한 고민을 하였습니다.
한발 더 들어가서 데이터 엔지니어의 업무를 깊게 분석해보는 과정에서 스트리밍 데이터를 처리하는 것에 매력을 느끼고 이 시스템을 안정적이고 확장가능한 구조를 설계하고 구축하는 역량을 키워야겠다는 필요성을 느꼈습니다.
“스트리밍 데이터를 다루는 비지니스가 뭐가 있을까?” 고민 하던 중 광고 도메인의 노출 대비 클릭의 비율(CTR)의 개념 발견 하였습니다. 추후 개인화된 광고 서비스에 사용될 수 있을 것 같다는 생각에 흥미를 느껴 주제로 선정하였습니다.
1.1 기능 파악
CTR은 조회수와, 클릭의 각 데이터가 카프카 이벤트가 들어오면 서버에서 수신하고 데이터를 가공합니다.
그러나 이벤트는 항상 시간 순서대로 도착하지 않고, 네트워크 지연과 파티션 편향 문제도 존재한다는 점을 파악했습니다.
따라서 정확한 윈도우 집계, 지연 이벤트 처리, 높은 처리량·낮은 지연을 동시에 만족하는 것이 중요하다고 판단되었습니다.
1.2 아키텍처 설계
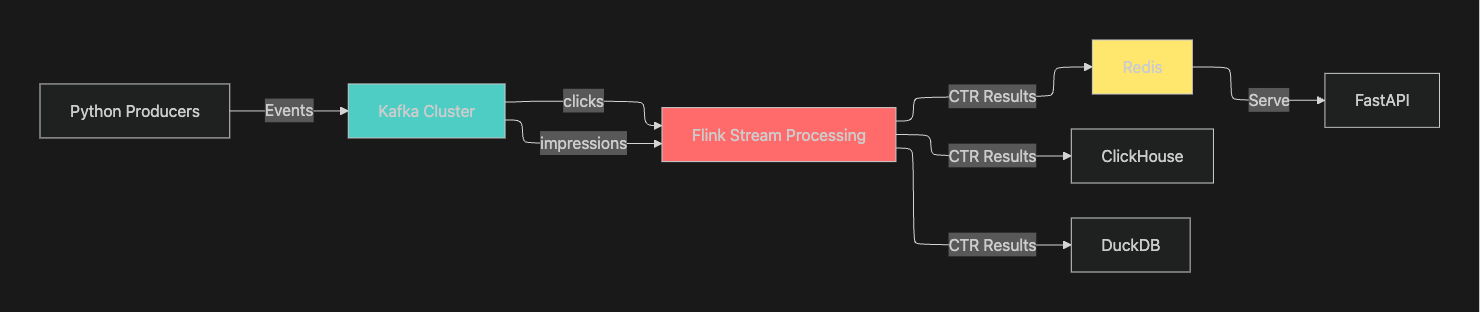
1.3 프로젝트 저장소
https://github.com/dev-wooyeon/demo-flink-product
2. 핵심 개념
2.1 CTR 계산이 스트림 처리에서 어려운 이유
-
Impression·Click 간의 시계열 상관성이 필요하다.
-
이벤트가 지연되거나 순서가 뒤바뀌어 도착할 수 있다.
-
CTR 계산은 짧은 시간 창(window) 단위로 이루어져야 한다.
-
Out-of-order 이벤트를 배제하면 정확성이 떨어지고, 과도하게 허용하면 지연(latency)이 증가한다.
2.2 이벤트 시간(Event Time) 기반 처리
Flink는 Processing Time 대신 Event Time 기반 처리를 권장한다.
본 파이프라인은 아래 기준으로 설계되었다.
-
워터마크(Watermark): 최대 5초 지연을 허용
-
텀블링 윈도우(Tumbling Window): 10초
-
Allowed Lateness: 추가 5초 허용
이 조합의 근거는 뒤의 Decision 섹션에서 상세히 설명한다.
2.3 상태(State) 기반 집계
CTR 계산의 기초 단위는 EventCount(Impression, Click 누적)이다.
윈도우마다 EventCount 상태가 만들어지고 업데이트된다.
코드는 Reference 섹션에서 제공한다.
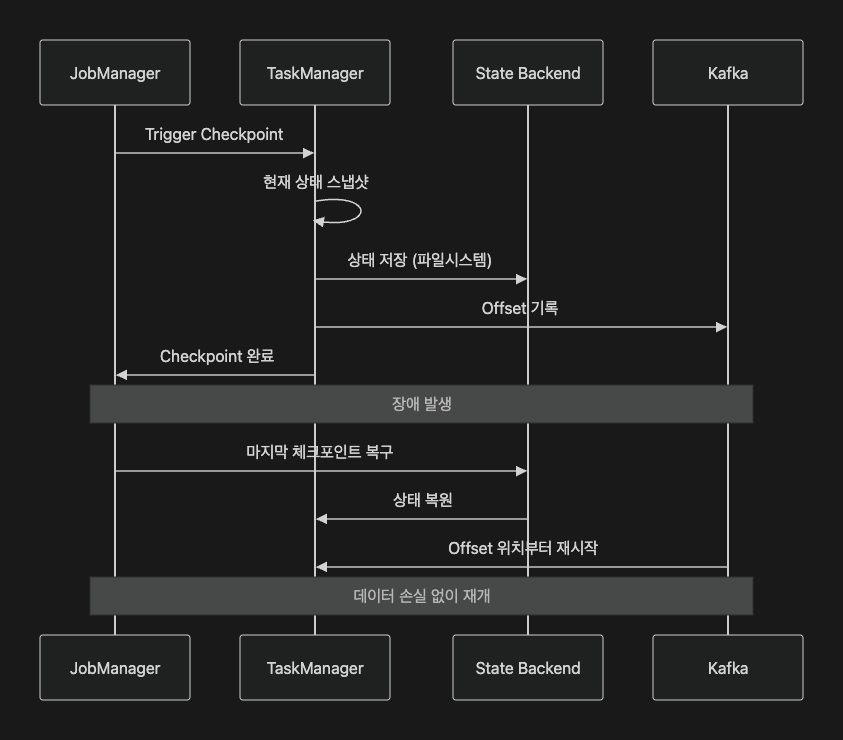
2.4 Exactly-Once보장
CTR은 작은 누락이나 중복도 큰 오차가 되므로 Exactly-Once 처리 모드는 필수다.
본 프로젝트는 다음을 기반으로 Exactly-Once를 보장한다.
-
Kafka offset을 체크포인트에 포함
-
Flink CheckpointingMode EXACTLY_ONCE
-
RETAIN_ON_CANCELLATION으로 안전한 상태 보존
3. 설계 의사결정
3.1 윈도우 길이 선택
아래는 실제 실험 기반 의사결정입니다.
-
5초
노이즈가 크고 CTR 값 변동이 지나치게 민감했습니다.
-
10초
지연·정확성·계산 안정성 비교적 균형적이여서 최종 선택하였습니다.
-
30초
응답성이 너무 낮고 실시간 모니터링 용도로 부적합해보였습니다.
3.2 Allowed Lateness 5초
지연 이벤트를 수용하지 않으면 CTR 정확도가 떨어졌습니다.
5초는 실제 네트워크 지연 분포에서 95% 지점에 해당하여 선택하였습니다.
3.3 워터마크 Out-of-Order 5초
워터마크 지연을 늘리면 정확도는 증가하지만 레이턴시는 증가합니다.
본 파이프라인은 Throughput–Latency 트레이드오프 상 최적값을 5초로 설정하였습니다.
3.4 멀티 싱크 전략 선택
싱크는 Redis, ClickHouse, DuckDB의 세 가지로 분리하는 방식으로 전략을 설정하였습니더.
-
Redis
서빙(실시간 API)용. 빠른(밀리초) 응답.
-
ClickHouse
OLAP 및 히스토리 분석용. (MergeTree Engine을 사용)
-
DuckDB
로컬 개발, 디버깅용
3.5 병렬도(Parallelism)와 파티션 대응
Kafka partitions = Flink 병렬도 = Sink 병렬도
이 정합이 깨지는 순간 Backpressure가 발생한다는 점을 알 수 있었습니다.
실험 결과로,
Parallelism 1에서는 Redis·ClickHouse가 포화되어 지연 급증하였습니다.
하드웨어는 Macbook Air M1, Memory 16GB 였습니다.
3.5.1 당시 도커 컨테이너 상태
| CONTAINER ID | NAME | CPU % | MEM USAGE / LIMIT | MEM % | NET I/O | BLOCK I/O |
|---|---|---|---|---|---|---|
| 4e796f1fb8cb | kafka-ui | 0.16% | 307.5MiB / 3.827GiB | 7.85% | 1.14MB / 2.85MB | 186MB / 117MB |
| cfef347c1c0b | kafka2 | 127.08% | 330.2MiB / 3.827GiB | 8.43% | 859MB / 929MB | 33.2MB / 319MB |
| 4288ee2e1646 | kafka3 | 41.49% | 293.9MiB / 3.827GiB | 7.50% | 698MB / 552MB | 34.4MB / 318MB |
| fbf6b8aa4bc4 | kafka1 | 77.39% | 345.4MiB / 3.827GiB | 8.81% | 811MB / 817MB | 81.9MB / 312MB |
| fb27f07ba10e | superset | 1.26% | 101.1MiB / 3.827GiB | 2.58% | 53.9kB / 2.3MB | 391MB / 163MB |
| 678f5e428704 | ctr-api | 0.60% | 23.31MiB / 3.827GiB | 0.59% | 261kB / 272kB | 60.9MB / 43.4MB |
| 45b518fceab4 | flink-taskmanager | 55.83% | 756.4MiB / 3.827GiB | 19.30% | 686MB / 262MB | 175MB / 332MB |
| 46ebe361fcda | redisinsight | 0.00% | 26.65MiB / 3.827GiB | 0.68% | 1.03MB / 65.8kB | 151MB / 67.2MB |
| c207c6890b09 | redis | 0.51% | 1.832MiB / 3.827GiB | 0.05% | 264kB / 252kB | 19.5MB / 2.98MB |
| d9bd0b068af2 | flink-jobmanager | 1.89% | 767.4MiB / 3.827GiB | 19.58% | 168MB / 168MB | 458MB / 459MB |
| ab8c8cfa95c5 | clickhouse | 8.72% | 310.9MiB / 3.827GiB | 7.93% | 293kB / 209kB | 558MB / 212MB |
| 5f09c7acfd18 | zookeeper | 7.05% | 80.93MiB / 3.827GiB | 2.07% | 228kB / 203kB | 70.2MB / 36.2MB |
3.5.2 Flink BackPressure 확인
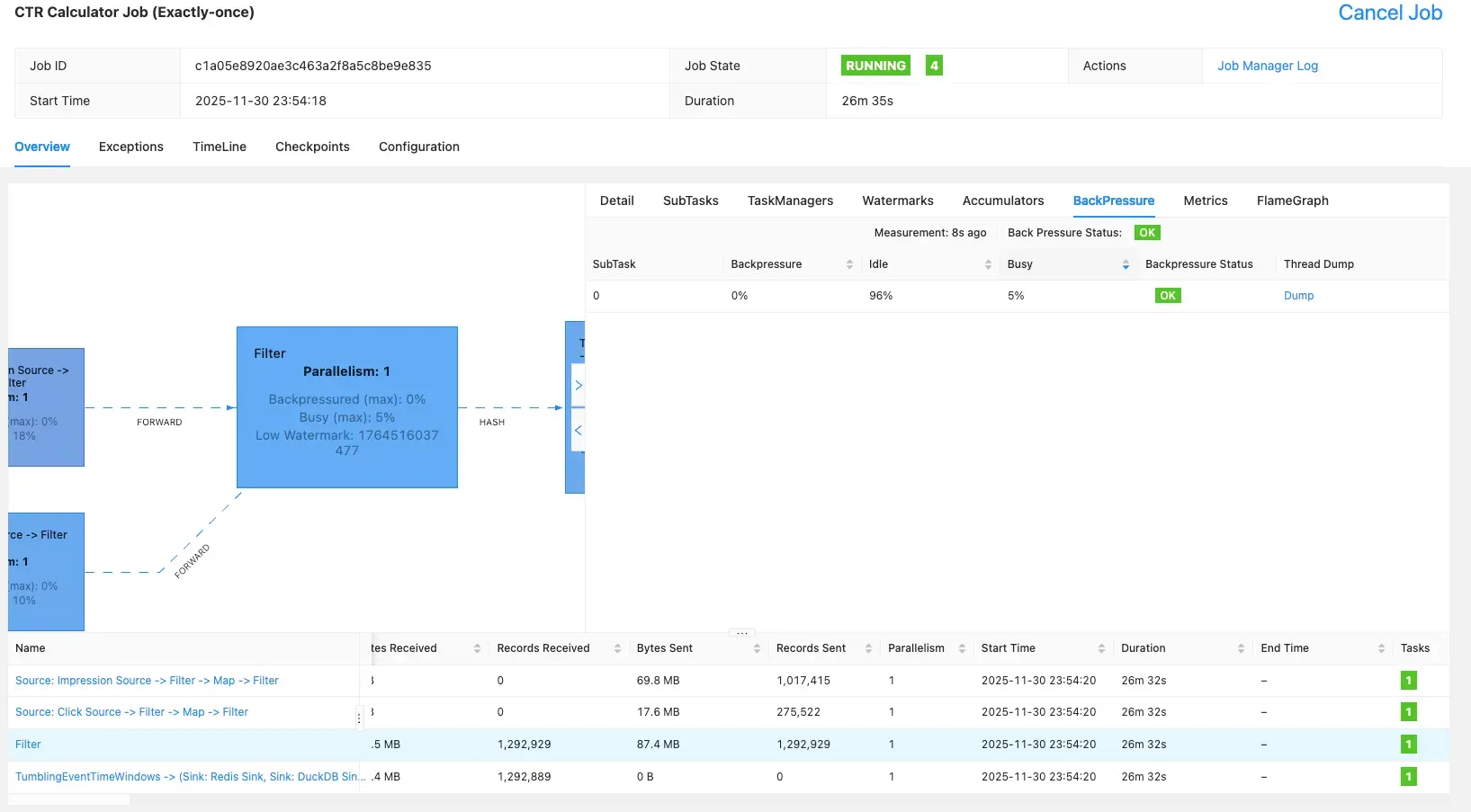
Flink UI를 확인 했을 때 초당 812건의 데이터를 처리할 수 있는 것을 확인할 수 있었고, 25분 정도 돌려 보았을 때 120만건 정도 처리할 수 있었습니다.
3.5.3 K6 Serving API 부하 테스트
█ THRESHOLDS
http_req_duration
✗ 'p(95)<1000' p(95)=6.41s
http_req_failed
✓ 'rate<0.01' rate=0.00%
response_time
✗ 'p(95)<1000' p(95)=6.41s
█ TOTAL RESULTS
checks_total.......: 450 12.054939/s
checks_succeeded...: 100.00% 450 out of 450
checks_failed......: 0.00% 0 out of 450
✓ status is 200
✓ json body is present
CUSTOM
response_time..................: avg=1.9s min=6ms med=1.12s max=8.42s p(90)=5.37s p(95)=6.41s
HTTP
http_req_duration..............: avg=1.89s min=6.09ms med=1.12s max=8.42s p(90)=5.37s p(95)=6.41s
{ expected_response:true }...: avg=1.89s min=6.09ms med=1.12s max=8.42s p(90)=5.37s p(95)=6.41s
http_req_failed................: 0.00% 0 out of 225
http_reqs......................: 225 6.02747/s
EXECUTION
dropped_iterations.............: 127 3.402172/s
iteration_duration.............: avg=1.9s min=6.78ms med=1.13s max=8.43s p(90)=5.38s p(95)=6.41s
iterations.....................: 225 6.02747/s
vus............................: 20 min=0 max=20
vus_max........................: 20 min=6 max=20
NETWORK
data_received..................: 194 kB 5.2 kB/s
data_sent......................: 18 kB 482 B/s
running (0m37.3s), 00/20 VUs, 225 complete and 0 interrupted iterations
ctr_load ✓ [======================================] 00/20 VUs 35s 10.00 iters/s
로컬 환경이라 서빙 API의 응답이 1초내로 동작하는 것을 기대했지만 노트북이 혹사당하여 응답 자체가 지연된다는 점을 확인할 수 있었습니다.
4. 시스템 구성
4.1 전체 데이터 흐름
Impressions/Clicks → Kafka → Flink → Redis/ClickHouse/DuckDB → FastAPI
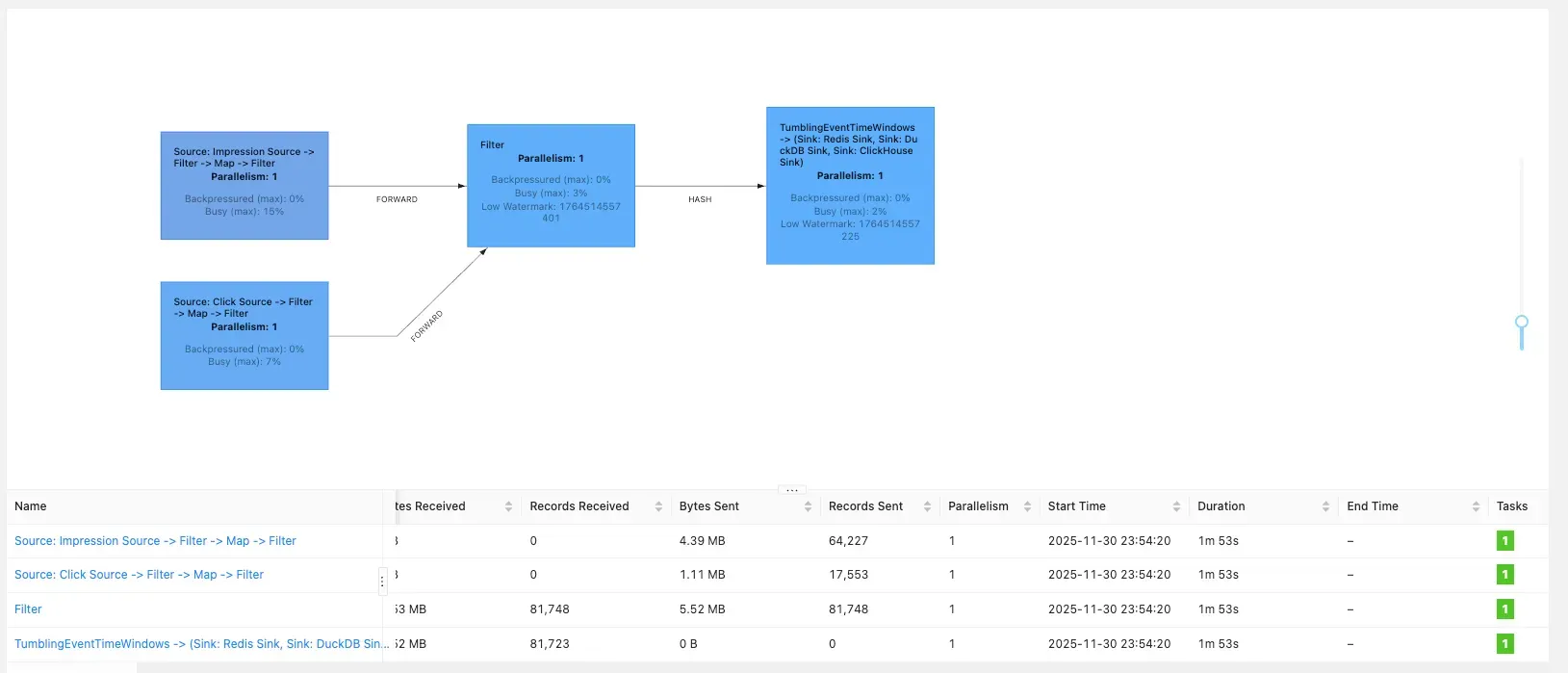
Flink는 웹 UI를 제공하고, Kafka랑 redis는 UI를 제공하지 않기 때문에, 직접 눈으로 보고 확인 할 수 있도록 각 provectuslabs/kafka-ui와 redis/redisinsight를 사용하여 확인 할 수 있었습니다.
4.2 Flink 파이프라인 단계

이벤트 생성부터 API 응답까지의 전체 흐름은,
Impression과 Click 이벤트가 각각 0.001초, 0.002초 간격으로 생성되어 Kafka 토픽으로 전송된다.
이후 Flink가 두 토픽의 데이터를 소비해서 10초 윈도우 단위로 CTR을 계산하고, 결과를 Redis에 저장한다.
저장된 Redis의 결과는 FastAPI를 통해 Redis에서 데이터를 읽어 REST API로 제공하는 흐름이다.
4.3 Flink 구성
4.3.1 핵심 설정
- 윈도우: 10초 Tumbling Window
- 시간 기준: Event Time
- 워터마크: 2초
- Allowed Lateness: 5초
CTR 같이 집계하는 비지니스는 이벤트 발생 시간으로 집계하는 것이 맞다고 판단했습니다.
Processing TIme을 사용하면 네트워크 지연이나 시스템 부하로인해 늦게 도착하는 이벤트들이 제외되거나 예외 사항이 발생할 수 있기 때문입니다.
Event Time을 사용하였으므로, 집계 시작 시간을 지정하기 위해 WaterMark를 2초로 설정하였고, Allowed Lateness는 5초를 할당하였습니다.
4.3.2 디렉토리 구조
flink-app/src/main/kotlin/com/example/ctr/
├── domain/ # 순수 비즈니스 로직
│ ├── model/
│ │ ├── Event.kt # 이벤트 도메인 모델
│ │ ├── EventCount.kt # 집계 상태
│ │ └── CTRResult.kt # CTR 계산 결과
│ └── service/
│ ├── EventCountAggregator.kt # 이벤트 집계
│ └── CTRResultWindowProcessFunction.kt # 윈도우 처리
├── application/ # 애플리케이션 서비스
│ └── CtrJobService.kt # Flink Job 오케스트레이션
├── infrastructure/ # 외부 시스템 연동
│ ├── flink/
│ │ ├── source/
│ │ │ ├── KafkaSourceFactory.kt
│ │ │ └── deserializer/
│ │ │ └── EventDeserializationSchema.kt
│ │ └── sink/
│ │ ├── RedisSink.kt
│ │ ├── ClickHouseSink.kt
│ │ └── DuckDBSink.kt
│ └── config/ # 설정
│ ├── CtrJobProperties.kt
│ ├── KafkaProperties.kt
│ └── RedisProperties.kt
└── CtrApplication.kt
4.4 인프라 구성
로컬 개발 환경과 프로덕션 환경의 일관성을 보장하기 위해 Docker Compose 기반으로 작성하였습니다.
services:
# Kafka 클러스터 (3 브로커)
kafka1:
image: confluentinc/cp-kafka:7.4.0
environment:
KAFKA_BROKER_ID: 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
# Flink 클러스터
flink-jobmanager:
image: flink:1.18-scala_2.12-java17
volumes:
- ./flink-app/build/libs:/opt/flink/usrlib # ShadowJar로 Flink에 배포 가능한 단일 JAR 생성.
# Redis (서빙 레이어)
redis:
image: redis:7.0-alpine
command: redis-server --appendonly yes
# ClickHouse (분석 DB)
clickhouse:
image: clickhouse/clickhouse-server:23.8
5. 운영 및 장애 대응
5.1 Backpressure 모니터링
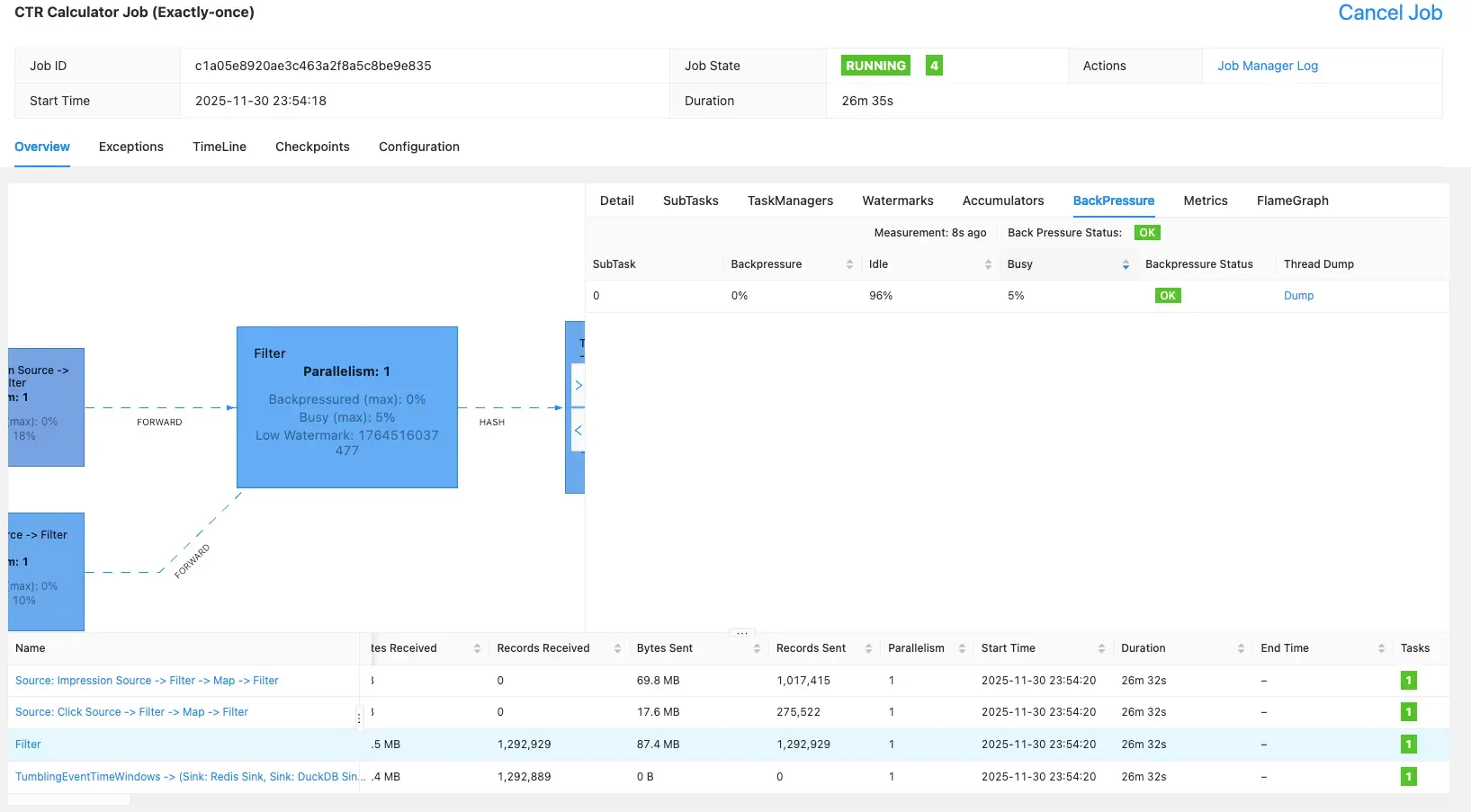
실험 결과
-
Kafka 소비 지연 증가
-
Redis RTT 증가
-
ClickHouse INSERT 지연
조치 방법
-
병렬도 증가
-
Redis pipeline 적용
-
ClickHouse batch size 조정.
5.2 체크포인트 장애
문제
배포 직후 체크포인트 타임아웃 연속 발생.
해결
-
주기·타임아웃 완화
-
병렬도 조정
-
상태 크기 감소(윈도우 상태 최소화)
5.3 파티션 skew
문제
productId 분포 불균형으로 특정 파티션만 lag 증가.
해결
- 파티션 3 → 6 → 12 증가
- 병렬도 정합 유지
6. 테스트 전략
6.1 단위 테스트
CTR 계산 테스트 (EventCountAggregator, CTRResult)
도메인 모델이 순수 로직이라 테스트 용이.
class CTRResultTest {
@Test
fun `CTR 계산 - 정상 케이스`() {
val result = CTRResult.calculate(
productId = "product1",
impressions = 100,
clicks = 10,
windowStart = 0L,
windowEnd = 10000L
)
assertThat(result.ctr).isEqualTo(0.1)
}
@Test
fun `CTR 계산 - impression이 0인 경우`() {
val result = CTRResult.calculate("product1", 0, 0, 0L, 10000L)
assertThat(result.ctr).isEqualTo(0.0)
}
}
6.2 통합 테스트
fromCollection → keyBy → window → aggregate 흐름 전체 검증.
@Test
fun `EventCountAggregator 통합 테스트`() {
val env = StreamExecutionEnvironment.getExecutionEnvironment()
env.setParallelism(1)
val events = listOf(
Event(eventType = "impression", productId = "p1", ...),
Event(eventType = "click", productId = "p1", ...)
)
val result = env.fromCollection(events)
.keyBy { it.productId }
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(EventCountAggregator())
.executeAndCollect()
assertThat(result.first().impressions).isEqualTo(1)
assertThat(result.first().clicks).isEqualTo(1)
}
7. API (Serving Layer)
7.1 FastAPI 엔드포인트
# serving-api/main.py
@app.get("/ctr/latest", summary="Get Latest CTR for All Products")
def get_all_latest_ctr(redis: Redis = Depends(get_redis)):
ctr_hash = redis.hgetall("ctr:latest")
if not ctr_hash:
return {}
result = {key: json.loads(value) for key, value in ctr_hash.items()}
return result
@app.get("/ctr/{product_id}")
def get_ctr_by_product_id(product_id: str, redis: Redis = Depends(get_redis)):
latest_json = redis.hget("ctr:latest", product_id)
previous_json = redis.hget("ctr:previous", product_id)
return {
"latest": json.loads(latest_json) if latest_json else None,
"previous": json.loads(previous_json) if previous_json else None
}
7.2 API 응답 예시
{
"product1": {
"productId": "product1",
"impressions": 523,
"clicks": 42,
"ctr": 0.0803,
"windowStart": 1701360000000,
"windowEnd": 1701360010000
},
"product2": {
"productId": "product2",
"impressions": 387,
"clicks": 15,
"ctr": 0.0388,
"windowStart": 1701360000000,
"windowEnd": 1701360010000
}
}
8. 기술 선택 이유
8.1 Flink vs Spark Streaming
-
낮은 지연
-
정교한 이벤트 시간 처리
-
풍부한 상태 관리
Spark는 마이크로배치가 강점이지만 CTR 같은 실시간 지표에는 부적합해보였습니다.
8.2 Spring Boot
Spring Boot는 과거 경험으로 익숙하고 Flink와 호환성이 좋아 선택하였습니다.
특히 Flink 1.18 버전부터 JDK 17 지원했기에 더 적합하다고 판단했습니다.
8.3 ClickHouse vs Snowflake/BigQuery
오픈소스로 설치하여 사용하는 경우 서버 비용만 내면 되기 때문에 장점이라고 판단하였고,
많은 대기업들에서 채택하여 Production환경에 사용될 만큼 안정적인 서비스라는 판단이 되었고
홈페이지 문서를 읽어보니 비교적 쉬운 접근성으로 판단되어 선택하였습니다.
8.4 DuckDB 활용 이유
ClickHouse는 다른 부서에서 사용할 수 있음으로 운영 중에 데이터를 건드리는 것은 위험하다고 판단했고,
저비용 OLAP 및 디버깅 용도로 활용가능할 것 같고, Observerlity를 고려했을 때 도입하는 것이 적당하다고 판단하였습니다.
9. 한계와 다음 단계
-
단일 노트북 기반 실험으로 실제 M개 TaskManager 환경 성능 검증 부족
→ 클라우드 기반 서버 구축 해보기 -
productId 외의 다차원 기준(광고그룹, 캠페인 등) 집계는 미지원
→ 광고 도메인에 대한 이해도 부족
-
멀티 리전 또는 WAN 환경에서 워터마크 설정 재검토 필요
→ 실제 업무 경험 필요해 보임
-
S3 기반 Lakehouse(Hudi·Iceberg) + ClickHouse Materialized View로 고도화 가능
→ minio 사용하여 로컬에서 테스트 해보기
10. 느낀점
단순 호기심에 시작했지만 스트리밍 데이터 파이프라인을 구축해보며 많은 학습을 통해 역량을 쌓을 수 있었는데요.
전에는 결과 중심적으로 학습을 이어가다 보니 왜 이렇게 설정해야하고 다르게 설정했을 떈 어떤 결과가 예측될지에 대한 이해가 많이 부족했다는 점을 꺠달았습니다.
이번 경험을 통해 이론이나 특히 공식문서의 중요성을 한번 더 깨달았고, 간단한 설정 하나가 시스템에 어마무시한 영향을 끼친다는 점을 알 수 있었습니다.
앞으로는 이론 중심의 학습을 이어나가며 지속적으로 성장 가능한 시스템을 구축하기 위해 노력하는 과정을 익히려고 합니다.
Code Agent를 활용하여 도움을 받긴 했지만 학습을 하지 않았더라면 정확하게 지시를 하지 못한다는 사실도 깨달았고 결국 검증하고 책임지는건 사람이라는것을 한번 더 깨달을 수 있었던 프로젝트였습니다.
언젠가 치열하게 살아오며 쌓아온 역량들을 실무에서 사용할 수 있는 날을 기대하며, 포스팅을 마무리합니다.